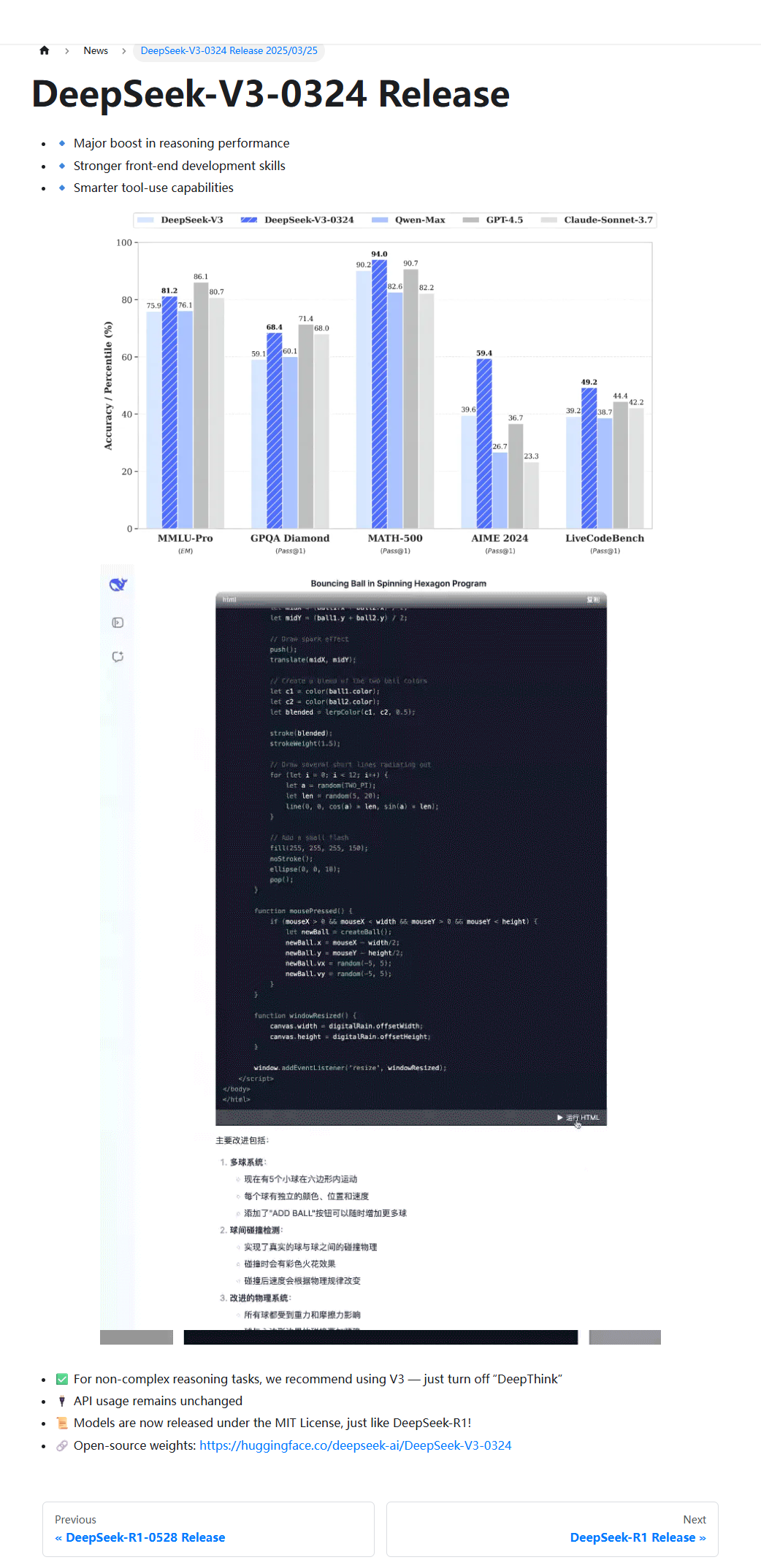
Key Features
- Advanced Architecture
-1. Mixed Expertise (MoE) architecture with 67.1 billion total parameters and 3.7 billion activations per marking.
-2. Multi-Leader Attention (MLA)
-3. DeepSeekMoE architecture
- Extensive training
-1. trained on 14.8 trillion diverse and high quality tokens
-2. Includes a higher proportion of math and programming data
- High Performance
1.Outperforms other open source models such as Llama 3.1 and Qwen 2.5.
2. Competes with leading closed-source models such as GPT-4o and Claude 3.5 Sonnet.
- Long Context Support
-1. Context length up to 128,000 tokens
- Function Capabilities
-1. Support for function calls
-2.JSON output
-3.FIM completion
- Open Source Availability
-1. available under the MIT license
-2. Model checkpoints accessible on GitHub (DeepSeek-V3 GitHub)