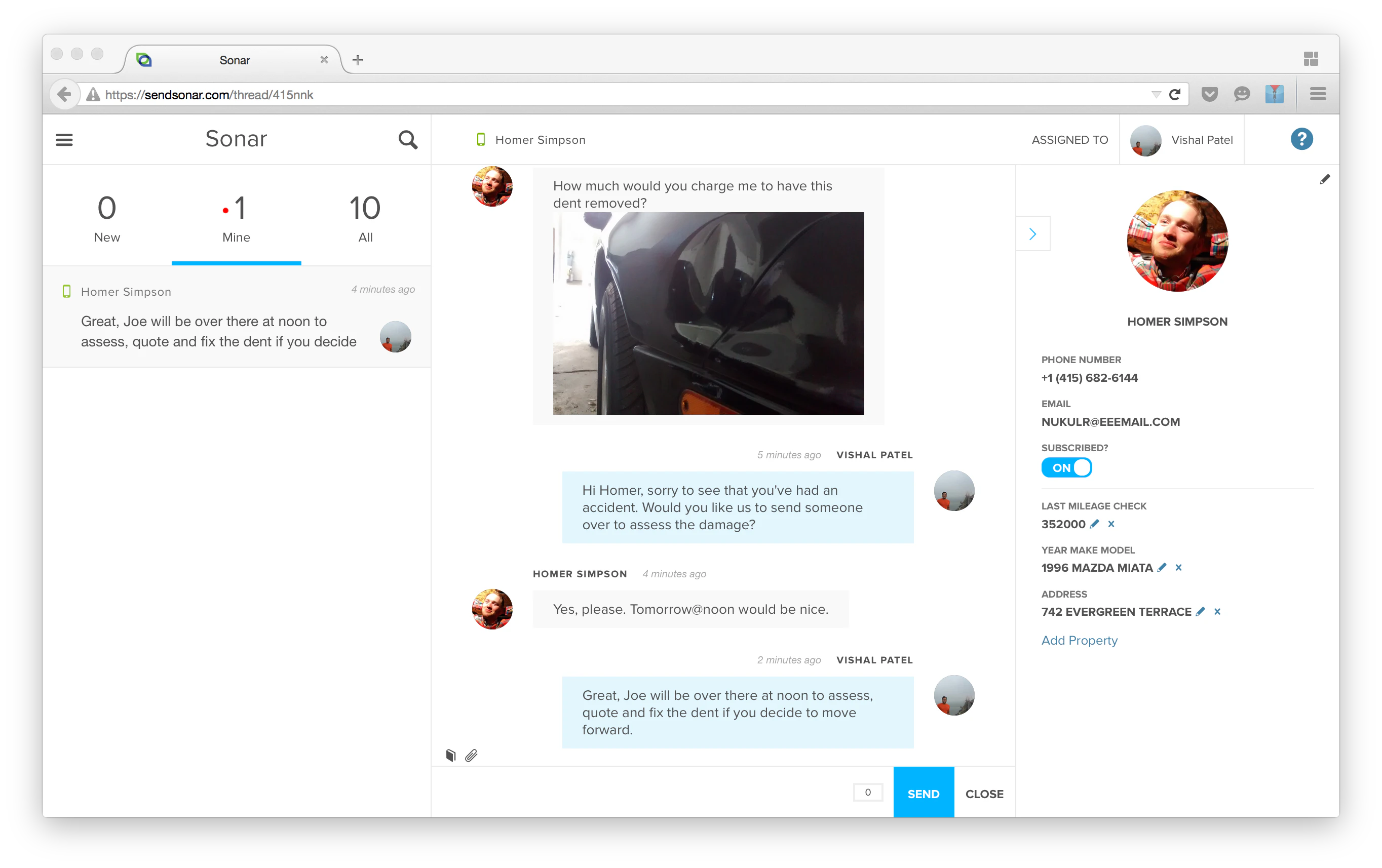
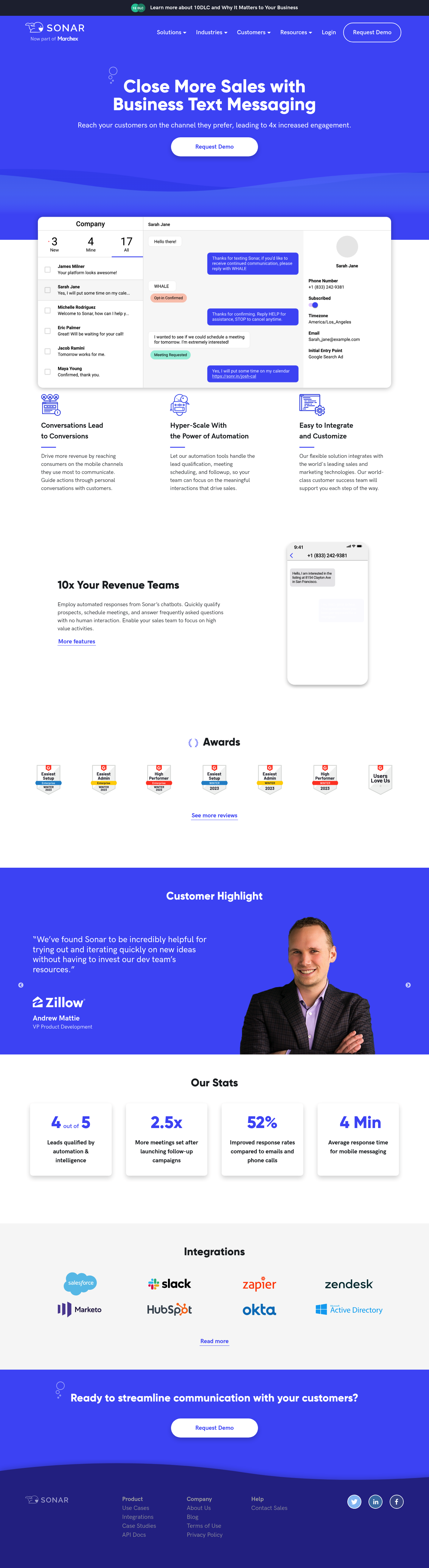
Send and receive SMS messages with customers effortlessly. Improve communication and boost engagement with the easiest SMS tool.
Sonar is an intelligent audio processing tool designed to enhance sound clarity and reduce background noise for professionals. It leverages advanced AI algorithms to deliver studio-quality audio, ensuring your recordings and communications are crisp and clear.
Remote workers, content creators, and podcasters looking for professional-grade audio solutions.
Give your agent a real number and voice to make calls.

AI Meeting companion with cross-meeting memory

An open source AI harness built with the human in mind

AI agents that turn signals into crypto + Polymarket trades

Skip the prompting. Produce consistently compelling videos.

Your Chief Agent Operator for multi-agent work

Grow your store profits with agents that know how to sell

An AI wearable that remembers your conversations all day

Al sleep companion that helps fall asleep without struggle

Scrape emails from socials and maps by location